MySQL的InnoDB索引原理詳解
本篇介紹下Mysql的InnoDB索引相關(guān)知識,從各種樹到索引原理到存儲的細(xì)節(jié)。
InnoDB是Mysql的默認(rèn)存儲引擎(Mysql5.5.5之前是MyISAM,文檔)。本著高效學(xué)習(xí)的目的,本篇以介紹InnoDB為主,少量涉及MyISAM作為對比。
這篇文章是我在學(xué)習(xí)過程中總結(jié)完成的,內(nèi)容主要來自書本和博客(參考文獻(xiàn)會給出),過程中加入了一些自己的理解,描述不準(zhǔn)確的地方煩請指出。
1 各種樹形結(jié)構(gòu)本來不打算從二叉搜索樹開始,因為網(wǎng)上已經(jīng)有太多相關(guān)文章,但是考慮到清晰的圖示對理解問題有很大幫助,也為了保證文章完整性,最后還是加上了這部分。
先看看幾種樹形結(jié)構(gòu):
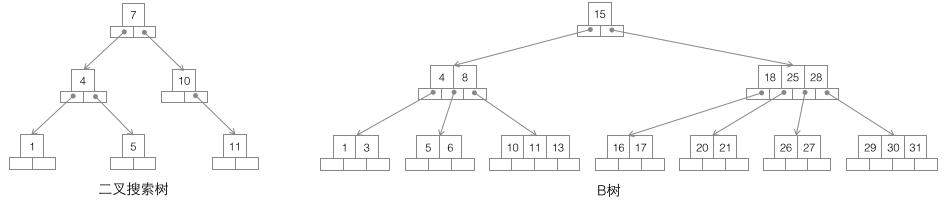
1 搜索二叉樹:每個節(jié)點有兩個子節(jié)點,數(shù)據(jù)量的增大必然導(dǎo)致高度的快速增加,顯然這個不適合作為大量數(shù)據(jù)存儲的基礎(chǔ)結(jié)構(gòu)。
2 B樹:一棵m階B樹是一棵平衡的m路搜索樹。最重要的性質(zhì)是每個非根節(jié)點所包含的關(guān)鍵字個數(shù) j 滿足:┌m/2┐ - 1 <= j <= m - 1;一個節(jié)點的子節(jié)點數(shù)量會比關(guān)鍵字個數(shù)多1,這樣關(guān)鍵字就變成了子節(jié)點的分割標(biāo)志。一般會在圖示中把關(guān)鍵字畫到子節(jié)點中間,非常形象,也容易和后面的B+樹區(qū)分。由于數(shù)據(jù)同時存在于葉子節(jié)點和非葉子結(jié)點中,無法簡單完成按順序遍歷B樹中的關(guān)鍵字,必須用中序遍歷的方法。
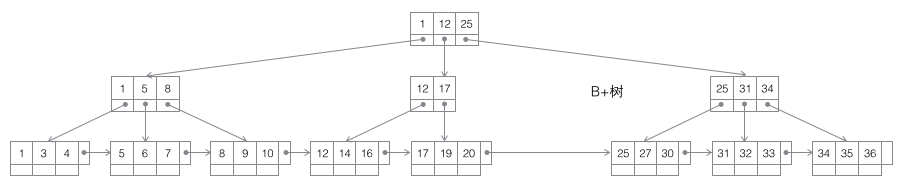
3 B+樹:一棵m階B樹是一棵平衡的m路搜索樹。最重要的性質(zhì)是每個非根節(jié)點所包含的關(guān)鍵字個數(shù) j 滿足:┌m/2┐ - 1 <= j <= m;子樹的個數(shù)最多可以與關(guān)鍵字一樣多。非葉節(jié)點存儲的是子樹里最小的關(guān)鍵字。同時數(shù)據(jù)節(jié)點只存在于葉子節(jié)點中,且葉子節(jié)點間增加了橫向的指針,這樣順序遍歷所有數(shù)據(jù)將變得非常容易。
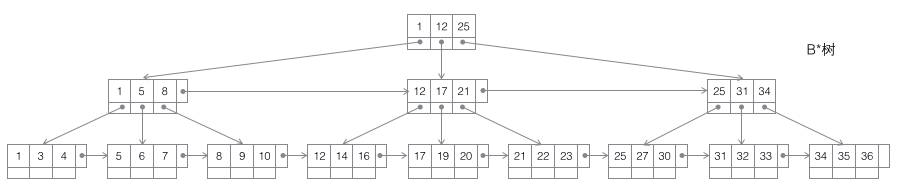
4 B*樹:一棵m階B樹是一棵平衡的m路搜索樹。最重要的兩個性質(zhì)是1每個非根節(jié)點所包含的關(guān)鍵字個數(shù) j 滿足:┌m2/3┐ - 1 <= j <= m;2非葉節(jié)點間添加了橫向指針。
B/B+/B*三種樹有相似的操作,比如檢索/插入/刪除節(jié)點。這里只重點關(guān)注插入節(jié)點的情況,且只分析他們在當(dāng)前節(jié)點已滿情況下的插入操作,因為這個動作稍微復(fù)雜且能充分體現(xiàn)幾種樹的差異。與之對比的是檢索節(jié)點比較容易實現(xiàn),而刪除節(jié)點只要完成與插入相反的過程即可(在實際應(yīng)用中刪除并不是插入的完全逆操作,往往只刪除數(shù)據(jù)而保留下空間為后續(xù)使用)。
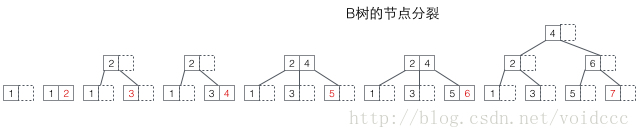
先看B樹的分裂,下圖的紅色值即為每次新插入的節(jié)點。每當(dāng)一個節(jié)點滿后,就需要發(fā)生分裂(分裂是一個遞歸過程,參考下面7的插入導(dǎo)致了兩層分裂),由于B樹的非葉子節(jié)點同樣保存了鍵值,所以已滿節(jié)點分裂后的值將分布在三個地方:1原節(jié)點,2原節(jié)點的父節(jié)點,3原節(jié)點的新建兄弟節(jié)點(參考5,7的插入過程)。分裂有可能導(dǎo)致樹的高度增加(參考3,7的插入過程),也可能不影響樹的高度(參考5,6的插入過程)。
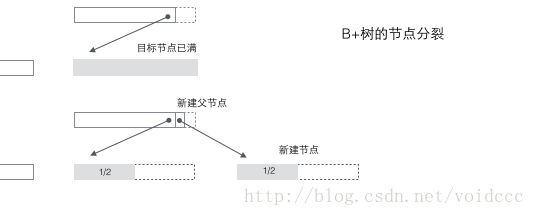
B+樹的分裂:當(dāng)一個結(jié)點滿時,分配一個新的結(jié)點,并將原結(jié)點中1/2的數(shù)據(jù)復(fù)制到新結(jié)點,最后在父結(jié)點中增加新結(jié)點的指針;B+樹的分裂只影響原結(jié)點和父結(jié)點,而不會影響兄弟結(jié)點,所以它不需要指向兄弟節(jié)點的指針。
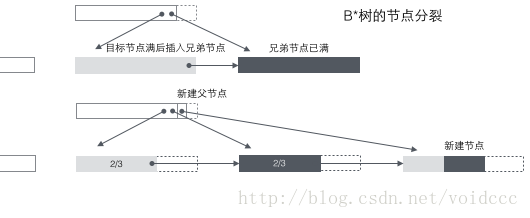
B*樹的分裂:當(dāng)一個結(jié)點滿時,如果它的下一個兄弟結(jié)點未滿,那么將一部分?jǐn)?shù)據(jù)移到兄弟結(jié)點中,再在原結(jié)點插入關(guān)鍵字,最后修改父結(jié)點中兄弟結(jié)點的關(guān)鍵字(因為兄弟結(jié)點的關(guān)鍵字范圍改變了)。如果兄弟也滿了,則在原結(jié)點與兄弟結(jié)點之間增加新結(jié)點,并各復(fù)制1/3的數(shù)據(jù)到新結(jié)點,最后在父結(jié)點增加新結(jié)點的指針。可以看到B*樹的分裂非常巧妙,因為B*樹要保證分裂后的節(jié)點還要2/3滿,如果采用B+樹的方法,只是簡單的將已滿的節(jié)點一分為二,會導(dǎo)致每個節(jié)點只有1/2滿,這不滿足B*樹的要求了。所以B*樹采取的策略是在本節(jié)點滿后,繼續(xù)插入兄弟節(jié)點(這也是為什么B*樹需要在非葉子節(jié)點加一個兄弟間的鏈表),直到把兄弟節(jié)點也塞滿,然后拉上兄弟節(jié)點一起湊份子,自己和兄弟節(jié)點各出資1/3成立新節(jié)點,這樣的結(jié)果是3個節(jié)點剛好是2/3滿,達(dá)到B*樹的要求,皆大歡喜。
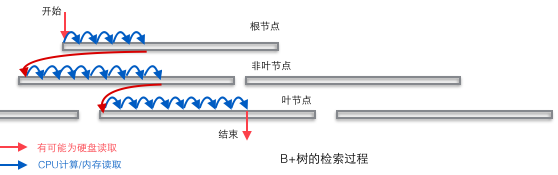
B+樹適合作為數(shù)據(jù)庫的基礎(chǔ)結(jié)構(gòu),完全是因為計算機(jī)的內(nèi)存-機(jī)械硬盤兩層存儲結(jié)構(gòu)。內(nèi)存可以完成快速的隨機(jī)訪問(隨機(jī)訪問即給出任意一個地址,要求返回這個地址存儲的數(shù)據(jù))但是容量較小。而硬盤的隨機(jī)訪問要經(jīng)過機(jī)械動作(1磁頭移動 2盤片轉(zhuǎn)動),訪問效率比內(nèi)存低幾個數(shù)量級,但是硬盤容量較大。典型的數(shù)據(jù)庫容量大大超過可用內(nèi)存大小,這就決定了在B+樹中檢索一條數(shù)據(jù)很可能要借助幾次磁盤IO操作來完成。如下圖所示:通常向下讀取一個節(jié)點的動作可能會是一次磁盤IO操作,不過非葉節(jié)點通常會在初始階段載入內(nèi)存以加快訪問速度。同時為提高在節(jié)點間橫向遍歷速度,真實數(shù)據(jù)庫中可能會將圖中藍(lán)色的CPU計算/內(nèi)存讀取優(yōu)化成二叉搜索樹(InnoDB中的page directory機(jī)制)。
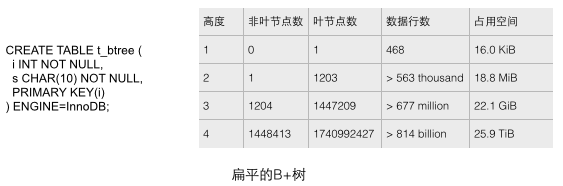
真實數(shù)據(jù)庫中的B+樹應(yīng)該是非常扁平的,可以通過向表中順序插入足夠數(shù)據(jù)的方式來驗證InnoDB中的B+樹到底有多扁平。我們通過如下圖的CREATE語句建立一個只有簡單字段的測試表,然后不斷添加數(shù)據(jù)來填充這個表。通過下圖的統(tǒng)計數(shù)據(jù)(來源見參考文獻(xiàn)1)可以分析出幾個直觀的結(jié)論,這幾個結(jié)論宏觀的展現(xiàn)了數(shù)據(jù)庫里B+樹的尺度。
1 每個葉子節(jié)點存儲了468行數(shù)據(jù),每個非葉子節(jié)點存儲了大約1200個鍵值,這是一棵平衡的1200路搜索樹!
2 對于一個22.1G容量的表,也只需要高度為3的B+樹就能存儲了,這個容量大概能滿足很多應(yīng)用的需要了。如果把高度增大到4,則B+樹的存儲容量立刻增大到25.9T之巨!
3 對于一個22.1G容量的表,B+樹的高度是3,如果要把非葉節(jié)點全部加載到內(nèi)存也只需要少于18.8M的內(nèi)存(如何得出的這個結(jié)論?因為對于高度為2的樹,1203個葉子節(jié)點也只需要18.8M空間,而22.1G從良表的高度是3,非葉節(jié)點1204個。同時我們假設(shè)葉子節(jié)點的尺寸是大于非葉節(jié)點的,因為葉子節(jié)點存儲了行數(shù)據(jù)而非葉節(jié)點只有鍵和少量數(shù)據(jù)。),只使用如此少的內(nèi)存就可以保證只需要一次磁盤IO操作就檢索出所需的數(shù)據(jù),效率是非常之高的。
可以說數(shù)據(jù)庫必須有索引,沒有索引則檢索過程變成了順序查找,O(n)的時間復(fù)雜度幾乎是不能忍受的。我們非常容易想象出一個只有單關(guān)鍵字組成的表如何使用B+樹進(jìn)行索引,只要將關(guān)鍵字存儲到樹的節(jié)點即可。當(dāng)數(shù)據(jù)庫一條記錄里包含多個字段時,一棵B+樹就只能存儲主鍵,如果檢索的是非主鍵字段,則主鍵索引失去作用,又變成順序查找了。這時應(yīng)該在第二個要檢索的列上建立第二套索引。 這個索引由獨(dú)立的B+樹來組織。有兩種常見的方法可以解決多個B+樹訪問同一套表數(shù)據(jù)的問題,一種叫做聚簇索引(clustered index ),一種叫做非聚簇索引(secondary index)。這兩個名字雖然都叫做索引,但這并不是一種單獨(dú)的索引類型,而是一種數(shù)據(jù)存儲方式。對于聚簇索引存儲來說,行數(shù)據(jù)和主鍵B+樹存儲在一起,輔助鍵B+樹只存儲輔助鍵和主鍵,主鍵和非主鍵B+樹幾乎是兩種類型的樹。對于非聚簇索引存儲來說,主鍵B+樹在葉子節(jié)點存儲指向真正數(shù)據(jù)行的指針,而非主鍵。
InnoDB使用的是聚簇索引,將主鍵組織到一棵B+樹中,而行數(shù)據(jù)就儲存在葉子節(jié)點上,若使用"where id = 14"這樣的條件查找主鍵,則按照B+樹的檢索算法即可查找到對應(yīng)的葉節(jié)點,之后獲得行數(shù)據(jù)。若對Name列進(jìn)行條件搜索,則需要兩個步驟:第一步在輔助索引B+樹中檢索Name,到達(dá)其葉子節(jié)點獲取對應(yīng)的主鍵。第二步使用主鍵在主索引B+樹種再執(zhí)行一次B+樹檢索操作,最終到達(dá)葉子節(jié)點即可獲取整行數(shù)據(jù)。
MyISM使用的是非聚簇索引,非聚簇索引的兩棵B+樹看上去沒什么不同,節(jié)點的結(jié)構(gòu)完全一致只是存儲的內(nèi)容不同而已,主鍵索引B+樹的節(jié)點存儲了主鍵,輔助鍵索引B+樹存儲了輔助鍵。表數(shù)據(jù)存儲在獨(dú)立的地方,這兩顆B+樹的葉子節(jié)點都使用一個地址指向真正的表數(shù)據(jù),對于表數(shù)據(jù)來說,這兩個鍵沒有任何差別。由于索引樹是獨(dú)立的,通過輔助鍵檢索無需訪問主鍵的索引樹。
為了更形象說明這兩種索引的區(qū)別,我們假想一個表如下圖存儲了4行數(shù)據(jù)。其中Id作為主索引,Name作為輔助索引。圖示清晰的顯示了聚簇索引和非聚簇索引的差異。
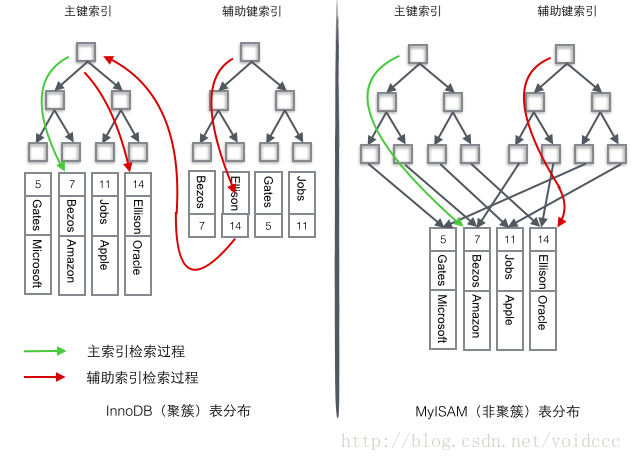
我們重點關(guān)注聚簇索引,看上去聚簇索引的效率明顯要低于非聚簇索引,因為每次使用輔助索引檢索都要經(jīng)過兩次B+樹查找,這不是多此一舉嗎?聚簇索引的優(yōu)勢在哪?
1 由于行數(shù)據(jù)和葉子節(jié)點存儲在一起,這樣主鍵和行數(shù)據(jù)是一起被載入內(nèi)存的,找到葉子節(jié)點就可以立刻將行數(shù)據(jù)返回了,如果按照主鍵Id來組織數(shù)據(jù),獲得數(shù)據(jù)更快。
2 輔助索引使用主鍵作為"指針" 而不是使用地址值作為指針的好處是,減少了當(dāng)出現(xiàn)行移動或者數(shù)據(jù)頁分裂時輔助索引的維護(hù)工作,使用主鍵值當(dāng)作指針會讓輔助索引占用更多的空間,換來的好處是InnoDB在移動行時無須更新輔助索引中的這個"指針"。也就是說行的位置(實現(xiàn)中通過16K的Page來定位,后面會涉及)會隨著數(shù)據(jù)庫里數(shù)據(jù)的修改而發(fā)生變化(前面的B+樹節(jié)點分裂以及Page的分裂),使用聚簇索引就可以保證不管這個主鍵B+樹的節(jié)點如何變化,輔助索引樹都不受影響。
3 Page結(jié)構(gòu)如果說前面的內(nèi)容偏向于解釋原理,那后面就開始涉及具體實現(xiàn)了。
理解InnoDB的實現(xiàn)不得不提Page結(jié)構(gòu),Page是整個InnoDB存儲的最基本構(gòu)件,也是InnoDB磁盤管理的最小單位,與數(shù)據(jù)庫相關(guān)的所有內(nèi)容都存儲在這種Page結(jié)構(gòu)里。Page分為幾種類型,常見的頁類型有數(shù)據(jù)頁(B-tree Node)Undo頁(Undo Log Page)系統(tǒng)頁(System Page) 事務(wù)數(shù)據(jù)頁(Transaction System Page)等。單個Page的大小是16K(編譯宏UNIV_PAGE_SIZE控制),每個Page使用一個32位的int值來唯一標(biāo)識,這也正好對應(yīng)InnoDB最大64TB的存儲容量(16Kib * 2^32 = 64Tib)。一個Page的基本結(jié)構(gòu)如下圖所示:
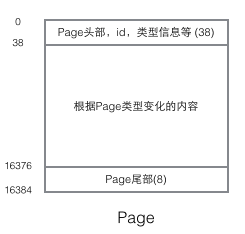
每個Page都有通用的頭和尾,但是中部的內(nèi)容根據(jù)Page的類型不同而發(fā)生變化。Page的頭部里有我們關(guān)心的一些數(shù)據(jù),下圖把Page的頭部詳細(xì)信息顯示出來:
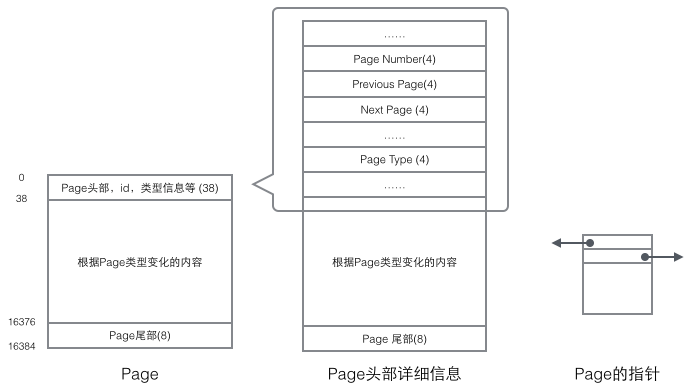
我們重點關(guān)注和數(shù)據(jù)組織結(jié)構(gòu)相關(guān)的字段:Page的頭部保存了兩個指針,分別指向前一個Page和后一個Page,頭部還有Page的類型信息和用來唯一標(biāo)識Page的編號。根據(jù)這兩個指針我們很容易想象出Page鏈接起來就是一個雙向鏈表的結(jié)構(gòu)。
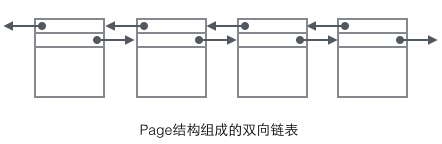
再看看Page的主體內(nèi)容,我們主要關(guān)注行數(shù)據(jù)和索引的存儲,他們都位于Page的User Records部分,User Records占據(jù)Page的大部分空間,User Records由一條一條的Record組成,每條記錄代表索引樹上的一個節(jié)點(非葉子節(jié)點和葉子節(jié)點)。在一個Page內(nèi)部,單鏈表的頭尾由固定內(nèi)容的兩條記錄來表示,字符串形式的"Infimum"代表開頭,"Supremum"代表結(jié)尾。這兩個用來代表開頭結(jié)尾的Record存儲在System Records的段里,這個System Records和User Records是兩個平行的段。InnoDB存在4種不同的Record,它們分別是1主鍵索引樹非葉節(jié)點 2主鍵索引樹葉子節(jié)點 3輔助鍵索引樹非葉節(jié)點 4輔助鍵索引樹葉子節(jié)點。這4種節(jié)點的Record格式有一些差異,但是它們都存儲著Next指針指向下一個Record。后續(xù)我們會詳細(xì)介紹這4種節(jié)點,現(xiàn)在只需要把Record當(dāng)成一個存儲了數(shù)據(jù)同時含有Next指針的單鏈表節(jié)點即可。
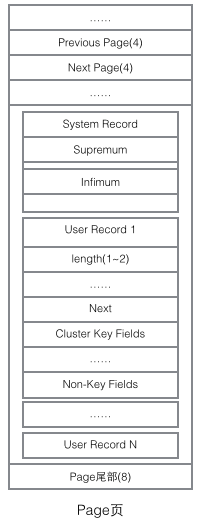
User Record在Page內(nèi)以單鏈表的形式存在,最初數(shù)據(jù)是按照插入的先后順序排列的,但是隨著新數(shù)據(jù)的插入和舊數(shù)據(jù)的刪除,數(shù)據(jù)物理順序會變得混亂,但他們依然保持著邏輯上的先后順序。
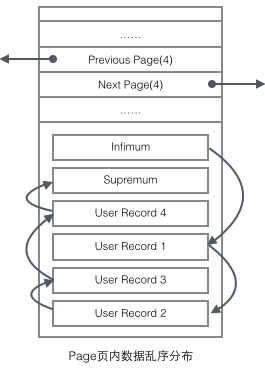
把User Record的組織形式和若干Page組合起來,就看到了稍微完整的形式。
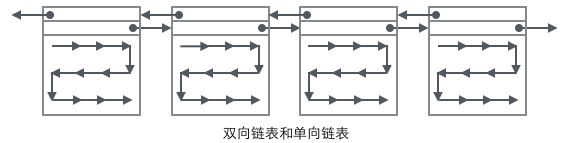
現(xiàn)在看下如何定位一個Record:
1 通過根節(jié)點開始遍歷一個索引的B+樹,通過各層非葉子節(jié)點最終到達(dá)一個Page,這個Page里存放的都是葉子節(jié)點。
2 在Page內(nèi)從"Infimum"節(jié)點開始遍歷單鏈表(這種遍歷往往會被優(yōu)化),如果找到該鍵則成功返回。如果記錄到達(dá)了"supremum",說明當(dāng)前Page里沒有合適的鍵,這時要借助Page的Next Page指針,跳轉(zhuǎn)到下一個Page繼續(xù)從"Infimum"開始逐個查找。
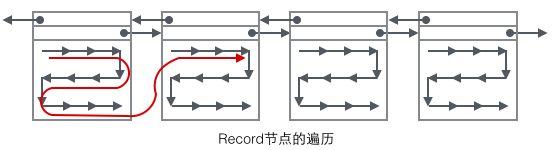
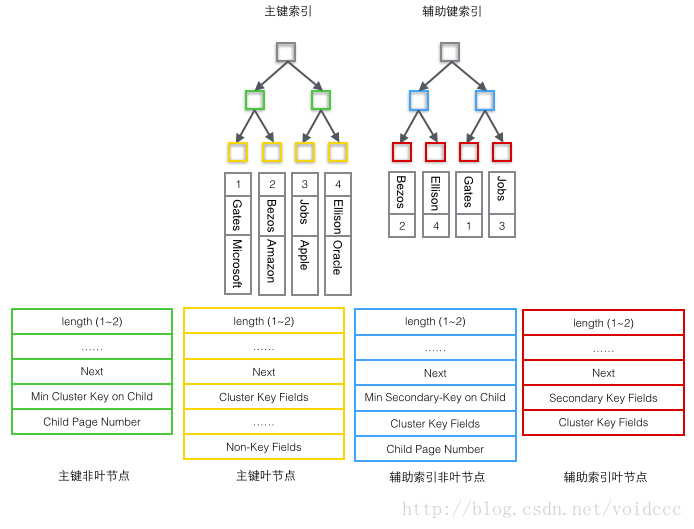
詳細(xì)看下不同類型的Record里到底存儲了什么數(shù)據(jù),根據(jù)B+樹節(jié)點的不同,User Record可以被分成四種格式,下圖種按照顏色予以區(qū)分。
1 主索引樹非葉節(jié)點(綠色)
1 子節(jié)點存儲的主鍵里最小的值(Min Cluster Key on Child),這是B+樹必須的,作用是在一個Page里定位到具體的記錄的位置。
2 最小的值所在的Page的編號(Child Page Number),作用是定位Record。
2 主索引樹葉子節(jié)點(黃色)
1 主鍵(Cluster Key Fields),B+樹必須的,也是數(shù)據(jù)行的一部分
2 除去主鍵以外的所有列(Non-Key Fields),這是數(shù)據(jù)行的除去主鍵的其他所有列的集合。
這里的1和2兩部分加起來就是一個完整的數(shù)據(jù)行。
3 輔助索引樹非葉節(jié)點非(藍(lán)色)
1 子節(jié)點里存儲的輔助鍵值里的最小的值(Min Secondary-Key on Child),這是B+樹必須的,作用是在一個Page里定位到具體的記錄的位置。
2 主鍵值(Cluster Key Fields),非葉子節(jié)點為什么要存儲主鍵呢?因為輔助索引是可以不唯一的,但是B+樹要求鍵的值必須唯一,所以這里把輔助鍵的值和主鍵的值合并起來作為在B+樹中的真正鍵值,保證了唯一性。但是這也導(dǎo)致在輔助索引B+樹中非葉節(jié)點反而比葉子節(jié)點多了4個字節(jié)。(即下圖中藍(lán)色節(jié)點反而比紅色多了4字節(jié))
3 最小的值所在的Page的編號(Child Page Number),作用是定位Record。
4 輔助索引樹葉子節(jié)點(紅色)
1 輔助索引鍵值(Secondary Key Fields),這是B+樹必須的。
2 主鍵值(Cluster Key Fields),用來在主索引樹里再做一次B+樹檢索來找到整條記錄。
下面是本篇最重要的部分了,結(jié)合B+樹的結(jié)構(gòu)和前面介紹的4種Record的內(nèi)容,我們終于可以畫出一幅全景圖。由于輔助索引的B+樹與主鍵索引有相似的結(jié)構(gòu),這里只畫出了主鍵索引樹的結(jié)構(gòu)圖,只包含了"主鍵非葉節(jié)點"和"主鍵葉子節(jié)點"兩種節(jié)點,也就是上圖的的綠色和黃色的部分。
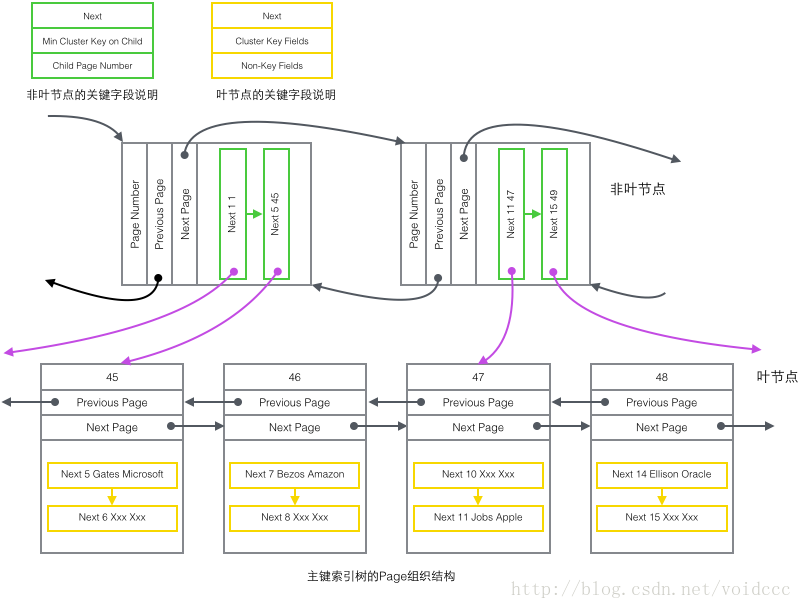
把上圖還原成下面這個更簡潔的樹形示意圖,這就是B+樹的一部分。注意Page和B+樹節(jié)點之間并沒有一一對應(yīng)的關(guān)系,Page只是作為一個Record的保存容器,它存在的目的是便于對磁盤空間進(jìn)行批量管理,上圖中的編號為47的Page在樹形結(jié)構(gòu)上就被拆分成了兩個獨(dú)立節(jié)點。
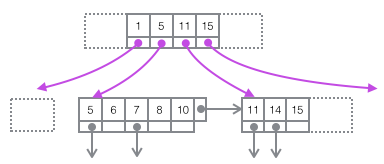
至此本篇就算結(jié)束了,本篇只是對InnoDB索引相關(guān)的數(shù)據(jù)結(jié)構(gòu)和實現(xiàn)進(jìn)行了一些梳理總結(jié),并未涉及到Mysql的實戰(zhàn)經(jīng)驗。這主要是基于幾點原因:
1 原理是基石,只有充分了解InnoDB索引的工作方式,我們才有能力高效的使用好它。
2 原理性知識特別適合使用圖示,我個人非常喜歡這種表達(dá)方式。
3 關(guān)于InnoDB優(yōu)化,在《高性能Mysql》里有更加全面的介紹,對優(yōu)化Mysql感興趣的同學(xué)完全可以自己獲取相關(guān)知識,我自己的積累還未達(dá)到能分享這些內(nèi)容的地步。
另:對InnoDB實現(xiàn)有更多興趣的同學(xué)可以看看Jeremy Cole的博客(參考文獻(xiàn)三篇文章的來源),這位老兄曾先后在Mysql,Yahoo,Twitter,Google從事數(shù)據(jù)庫相關(guān)工作,他的文章非常棒!
相關(guān)文章:
1. Mybatis批量插入返回插入成功后的主鍵id操作2. MySql使用mysqldump 導(dǎo)入與導(dǎo)出方法總結(jié)3. MariaDB中1045權(quán)限錯誤導(dǎo)致拒絕用戶訪問的錯誤解決方法4. Microsoft Office Access刪除表記錄的方法5. 如何用mysqldump進(jìn)行全量和時間點備份6. 失而復(fù)得:Oracle數(shù)據(jù)庫表空間恢復(fù)方案7. DB2 V9.5工作負(fù)載管理之閾值(THRESHOLD)8. 安裝配置mysql及Navicat prenium的詳細(xì)流程9. Row_number()函數(shù)用法小結(jié)10. DB2中實現(xiàn)Oracle的相關(guān)功能

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備