文章詳情頁
用python中的xpath怎么獲取我想要標記的內容
瀏覽:155日期:2022-06-30 11:01:03
問題描述
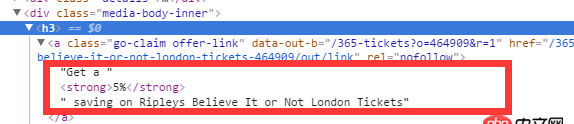
我想獲取h3下面a標簽下的完整內容(Get a 5% saving on Ripleys Believe It or Not London Tickets),這個用xpath怎么獲取呢?跪求高手指教
問題解答
回答1:最方便的辦法,選中,有個復制到xpath的選項
回答2:chrome下右擊 元素copy->Copy XPath
回答3:之前的答案并沒有針對樓主的問題,因為樓主沒有將問題描述清楚,我想樓主想說的是直接用text() 方法或text屬性得不到子標簽內的內容(假設你已經看過了xpath的基本語法)。Google搜索xpath get all text, 第一個就是答案。樓主可以這樣提問:xpath如何取出被標簽包含的文字內容(雖然這里的答案并不能讓人滿意)
回答4:你試試
response.xpath(’//h3/a/descendant-or-self::text()[normalize-space()]’)
descendant-or-self表明當前node和子代nodes
normal-space()去掉whitespace-only nodes的子代nodes(這個可要可不要)
參考鏈接:http://stackoverflow.com/ques...
相關文章:
1. vue.js - vue 打包后 nginx 服務端API請求跨域問題無法解決。2. Pycharm中文輸出亂碼怎么辦?win10,Pycharm3.2,Python3.53. docker綁定了nginx端口 外部訪問不到4. html - 【css】讓div居中的方法失效了,我該如何改?(在不用css3和表格的情況下)。謝謝。5. angular.js - 如何不通過微信的JSSDK實現圖片預覽功能6. node.js - 微信小程序服務端websocket配置7. javascript - 切換掉當前頁面后該頁面的js動畫會暫停?8. PHP單例模式9. css3 - 使用less編譯css后,后期的項目中less是直接放在項目文件中,后期如何維護呢10. 網頁爬蟲 - 為什么python模擬登陸 appannie一直返回503 code
排行榜

 網公網安備
網公網安備